- Where are these images located?
- How do I embed the image into a dashboard or report?
- How do I maintain the integrity of the image URL across multiple environments?
Where are these images located?
All images are stored in the 'browser look and feel plus' folder of the BI Server, you've probably seen this notated as 's_bflap'. This folder exists in two locations and it is critical that any image you upload be housed in both:- Oracle_BI1\bifoundation\web\app\res\s_blafp\images
- user_projects\domains\bifoundation_domain\servers\bi_server1\tmp\_WL_user\analytics_11.1.1\7dezjl\war\res\s_blafp\images
How do I embed the image into a dashboard or report?
OBIEE 11g has a little known feature called 'fmap' which can be used to display an image based on the relative URL of the image. Little documentation exists on it other than a few notes released by Oracle which include:- How To Display Custom Images Using Fmap In OBIEE 11g (Doc ID 1352485.1)
- Image FMAP on Linux (Doc ID 491154.1)
How do I maintain the intregrity of the image URL across multiple environments?
Here is where things get tricky due to the lack of documentation that exists. Let's say you want to use the image 'report_good_percentage.jpg' located in the s_blafp folder:
So as outlined in Oracle's documentation you use
'fmap:report_good_percentage.jpg' or even
'fmap:images/report_good_percentage.jpg', but to your dismay all you see
is a broken image link:

Why?
It is important to remember that fmap displays the image of the relative
URL. So what does relative mean? What is 'it' relative to? In regards
to fmap, the relative URL is the root directory of the analytics web
server, which in OBIEE 11g is:
Which makes sense if you understand how applications are deployed in weblogic. The presence of the WEB-INF directory in the aforementioned folder is how Weblogic determines if a folder if a deployable application directory.
/export/obiee/11g/user_projects/domains/bifoundation_domain/servers/bi_server1/tmp/_WL_user/analytics_11.1.1/7dezjl/war
So - if we work under the assumption that the above folder is indeed the root directory, then it we now know why the image returns a broken link, report_good_percentange.jpg is not stored in the 'root' directory of the analytics web server, it is actually stored in:
/export/obiee/11g/user_projects/domains/bifoundation_domain/servers/bi_server1/tmp/_WL_user/analytics_11.1.1/7dezjl/war/res/s_blafp/imagesLet's update the fmap relative url to correctly reference report_good_percentage.jpg by modifying it to:
fmap:res/s_blafp/images/report_good_percentage.jpgUnfortunately..

Why does fmap STILL not work?
Let's take a look at the URL that's actually being generated:
Notice anything funny? Why is OBIEE 11g adding a 'Missing_' folder to
the URL directory? Countless bloggers have theorized this as a bug in
OBIEE and some even suggest making a 'Missing_' folder in the root
directory of the analytics web server. I don't think that is the best
approach because as you deploy this application across multiple servers,
you'll have to make sure all environments have that same folder. Keep
it simple right?
We can resolve this by modifying the fmap url to revert one directory closer to its root by using '/..':
fmap:/../res/s_blafp/images/report_good_percentage.jpg
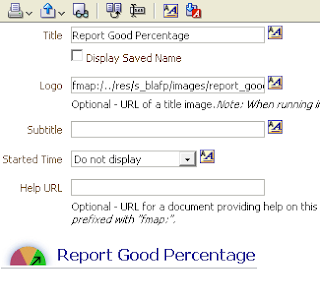
Let's check the URL being generated just to make sure:

The image displays, and the 'Missing_' folder is no where to be found.
If your requirements have extensive image customizations, perhaps
changing the entire look and feel, I recommend deploying an entirely new
skin as outlined in Oracle Note: How to Use Custom Images in OBIEE (Doc ID 1484623.1)