Yet when researching for comprehensive guides on how to actually implement a bridge table in OBIEE 11g, the documentation available is either:
- Out of date
- Contains implementation steps for OBIEE 10g which has since been deprecated
- Does not contain adequate detail
- e.g. missing key steps
This guide is going to outline the basic use case of a many to many
relationship, how OBIEE 11g resolves this dilemma and how to
successfully implement a bridge table model within the 11g platform.
First thing's first - what is a bridge table and why do we need it?
At its core, bridge table solve the many to many relationship we
encounter in many datasets. Many to many relationships in itself are not
"bad", but when attempting to conform a data set to a star schema -
many to many relationships just do not work. Star schemas assume a one
to many (1:N) cardinality from the dimension to the fact. This means
"one attribute of a dimension row can be found in many rows of the fact
table".
For Example:
- One job (job dimension) can be performed by many people
- You would see the same JOB_WID repeating in the fact table
- One employee (employee dimension) can have many jobs
- You would see the same EMPLOYEE_WID repeating in the fact table
- One call at a call center(ticket dimension) can have many ticket types
- You would see the same CALL_WID repeating in the fact table
- One patient (patient dimension) can have many diagnosis
- You would see the same PATIENT_WID repeating in the fact table
This 1:N cardinality is represented in OBIEE as (using call center/employee example) :

"Cardinality of '1' applied to the dimension and cardinality of 'N' applied to the fact'
But what happens when in the above examples, the cardinality is actually N:N?
For Example:- Many employees can have multiple jobs and each job can be performed by multiple employees
- Many patients can have multiple diagnosis and each diagnosis can be 'assigned' to many patients
- Many calls can have multiple call ticket types and each ticket type can belong to multiple calls
This many to many relationship is initially (and incorrectly) represented in OBIEE 11g as:
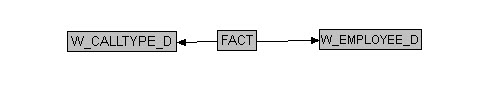
'Cardinality of '1' is applied to the two dimension tables and cardinality of 'N' is applied to the fact'
Any BI Architect should recognize the
above model - it's a traditional star schema! If you stop here and
decided to ignore the issue with your dataset and 'hope' OBIEE
aggregates the model correctly, you're about to be disappointed.
Why star schemas dont work for N:N cardinality
Consider the following scenario: You're a call center manager and you
want to capture the number of calls with positive feedback per employee.
You also want to capture the type of calls an employee answers in any
given day.
Upon analysis of the requirements you conclude that "each call received
by an employee can have many call types and each call type can be
answered by multiple employees".
For example:
- I answer a take a call that is classified as a 'new call', 'urgent', and 'out of state transfer' (three different call types) - this is the "each call received by an employee can have many call types".
- A colleague also received a phone call that is classified as 'out of state transfer' - this is the 'each call type can be answered by multiple employees"
Now let's put this data in a traditional star schema fact table as modeled below:

| ID | EMPLOYEE_WID | CALL_TYPE_WID | NUMBER_OF_GOOD_CALLS |
| 1 | 1 | 1 | 300 |
| 2 | 1 | 2 | 300 |
| 3 | 1 | 3 | 300 |
| 4 | 2 | 2 | 500 |
| 5 | 2 | 3 | 500 |
| 6 | 3 | 1 | 200 |
- EMPLOYEE 1:
- Has 3 different call types
- Has 300 positive reviews (NUMBER_OF_GOOD_CALLS)
- This metric is at the EMPLOYEE level and not the call type level!
- EMPLOYEE 2:
- Has 2 different call types
- Has 500 positive reviews (NUMBER_OF_GOOD_CALLS)
- This metric is at the EMPLOYEE level and not the call type level
- EMPLOYEE 3:
- Has 1 different call type
- Has 200 positive reviews (NUMBER_OF_GOOD_CALLS)
PROBLEM 1 - Aggregation :

- Employee 1 received 300 good calls
- Employee 2 received 500 good calls
- Employee 3 received 200 good calls
but due to the many to many cardinality of the data, the star schema
duplicates the measures because each employee can take calls of many
call types and each call type can be assigned to many employees!
PROBLEM 2 - Grand Totaling:
What if you don't care about aggregates? What if you just want a report that contains the employee, call type and a summation/grand total?

Notice how NUMBER_OF_GOOD_CALLS is repeated across multiple call types and the grand total is still incorrect. It's being duplicated due to the many to many relationship that exists between call type and employee. Furthermore, it paints an incorrect picture that NUMBER_OF_GOOD_CALLS is some how related to CALL_TYPE
How do we resolve this many to many cardinality with a bridge table?
When all is said and done, the incorrectly built star schema:

Let's break this down:
The bridge table:
This the purpose of the bridge table is to resolve the many to many
relationship between the call type and employee. It will contain, at a
minimum, the following four columns:
- The primary key of the table
- The EMPLOYEE_WID
- The CALLTYPE_WID
- The weight factor
The weight factor is what's going to resolve the issue of double counting.
- If an employee has 3 call types, there would be 3 rows and the weight factor of each row would be .33
- If an employee has 10 call types, there would be 10 rows and the weight factor of each row would be .1
In our bridge table data set, we're going to use the same 3 EMPLOYEE_WIDs and create the following:
| ID | CALL_TYPE_WID | EMPLOYEE_WID | WEIGHT |
| 11 | 1 | 1 | 0.33 |
| 12 | 2 | 1 | 0.33 |
| 13 | 3 | 1 | 0.33 |
| 23 | 2 | 2 | 0.5 |
| 24 | 3 | 2 | 0.5 |
| 31 | 1 | 3 | 1 |
The dimension that is joined to both the fact and bridge
This is a generic dimension that contains the unique EMPLOYEE IDs in your organization's dataset.
For example:
| ID | EMPLOYEE_ID |
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
| 4 | 4 |
| 5 | 5 |
| 6 | 6 |
| 7 | 7 |
| 8 | 8 |
| 9 | 9 |
| 10 | 10 |
The dimension that is joined to only the bridge table
This dimension contains all of the possible call types. Note how this table is not physically joined to the fact. This is because this specific dimension (CALL_TYPE) is what's causing the N:N cardinality
For example:
| ID | DESC |
| 1 | Call Type 1 |
| 2 | Call Type 2 |
| 3 | Call Type 3 |
| 4 | Call Type 4 |
| 5 | Call Type 5 |
| 6 | Call Type 6 |
| 7 | Call Type 7 |
| 8 | Call Type 8 |
| 9 | Call Type 9 |
| 10 | Call Type 10 |
The Fact Table
We've moved the N:N cardinality from the original fact table to the bridge table so the new fact table now contains exactly one row per employee and does not have the CALL_TYPE_WID.
| ID | EMPLOYEE_WID | NUMBER_OF_GOOD_CALLS |
| 1 | 1 | 300 |
| 2 | 2 | 500 |
| 3 | 3 | 200 |
How do we implement this model in OBIEE 11g?
Step 1: Import Tables into Physical Layer
This is always the first step performed when creating a model regardless of its type. In the above example i'm importing four tables:


Step 3: Create the Logical Data Model
The creation of the BMM is where we deviate from our standard build steps of a traditional star schema:

Step 3.2: Create a 2nd LTS in the existing dimension table









This is always the first step performed when creating a model regardless of its type. In the above example i'm importing four tables:

Step 2: Create the Physical Data Model
Based on our data set above the join conditions would be implemented as follows:
- 1:N relationship from employee dimension to fact table
- 1:N relationship from employee dimension to bridge
- 1:N relationship from call type dimension to bridge
Notice how employee_demo_d is the only dimension that is joined to the
fact. w_call_type_d is not joined to the fact because that is the
dimension that is causing the many to many relationship issue.

Step 3: Create the Logical Data Model
The creation of the BMM is where we deviate from our standard build steps of a traditional star schema:
- All associated dimension tables referencing the bridge table will be stored in a single BMM table
- The single BMM table will have two logical table source
Step 3.1 : Drag the fact table and dimension table that is connected to the fact table into the BMM.
In our example, we are dragging w_calls_f and w_employee_demo_d into the BMM:
Step 3.2: Create a 2nd LTS in the existing dimension table
- Right click W_EMPLOYEE_DEMO_D -> New Object -> New Logical Table Source
- Name it 'Bridge'
- Add W_BRIDGE_D and W_CALLTYPE_DEMO_D (the two dimensions not directly joined to the fact table) under the 'Map to these tables' section

- Next add the remaining dimension columns from W_CALLTYPE_DEMO_D and W_BRIDGE_DEMO_D to the Dimension table in the BMM

Step 3.3: Create a level-based dimension hierarchy for the dimension BMM
- This step should be completed whether or not the schema is a star or bridge

Step 3.4: Confirm the BMM model has a 1:N relationship from the dimension to fact

Step 3.5: Set aggregation rule of NUMBER_OF_GOOD_CALLS to sum
All measures in the BMM must have a mathematical operation applied to the column

Step 3.5: Set the Content level of the dimension table to 'detail' in within the LTS of the fact table
Again, this is something that should always take place regardless of the type of model

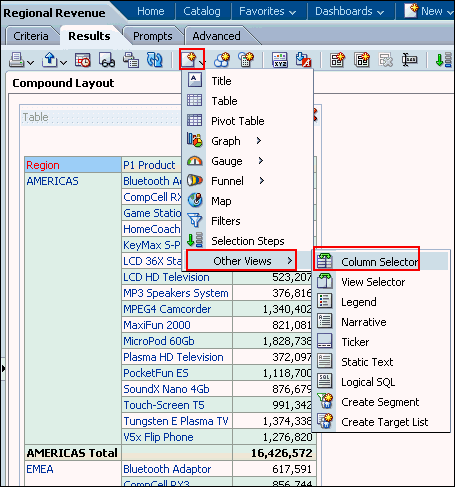
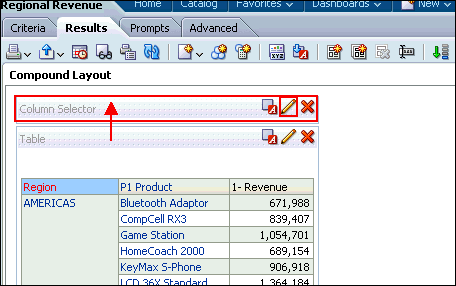
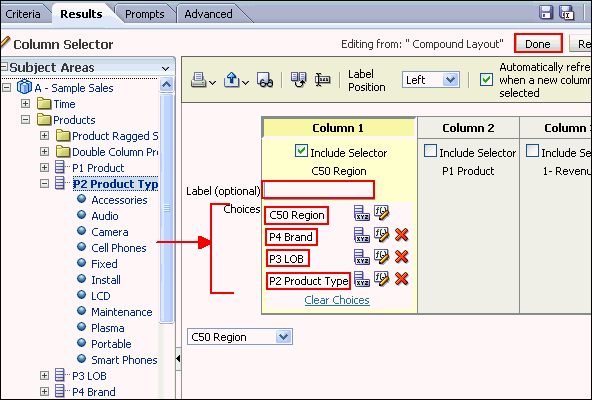
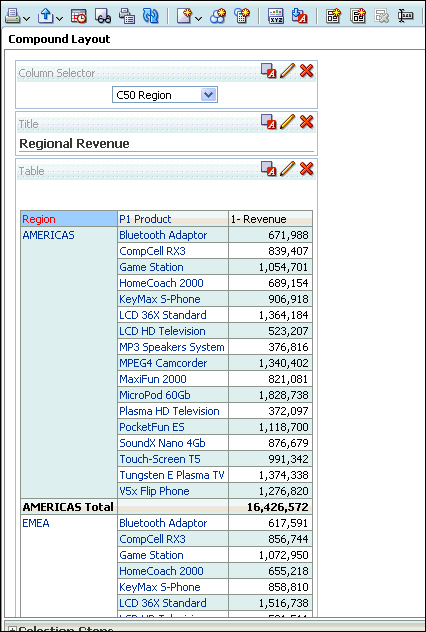
Step 4: Create the Presentation Layer
This part is straight forward, just drag the folders from the BMM into the new subject area:

The moment of truth
So why did we go through this elaborate exercise again? To fix the
aggregation issues we were having with NUMBER_OF_GOOD_CALLS due to the
N:N cardinality of the data set. Let's create that 'standalone KPI'
Number of Good Calls:

Notice how the metric correctly sums to 1000. Let's check the back end physical query to confirm:

Notice how it's hitting the fact table and not the bridge or the call type dimension.
But what about the weight factor?
Let's go back to the scenario where we want to compare across dimensions joined via the bridge table (EMPLOYEE and CALL_TYPE):
- When creating a report that uses a measure from the fact table, a dimension value from the the employee table, and a dimension value from the table that causes the N:N cardinality - you need to use the weight factor to make sure your measure isn't getting double or triple counted:
 |
In order for grand totaling to work
correctly with bridge table measures that use weight facts you must set
the aggregation rule of the column (in this case column 1) to sum within
Answers:
 
So what did we accomplish in this guide?
|